建立网站需要多少钱八寇湖南岚鸿团队搜索引擎营销的常见方式
TensorFlow的数据读取方式
TensorFlow的数据读取方式共有三种,分别是:
①预加载数据(Preloaded data)
预加载数据的方式,其实就是静态图(Graph)的模式。即将数据直接内嵌到Graph中,再把Graph传入Session中运行。
示例代码如下:
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()a = tf.constant([[5,2]])
b = tf.constant([[1],[3]])
c = tf.matmul(a,b)init = tf.global_variables_initializer()
with tf.Session() as sess:sess.run(init)print(sess.run(c))
②先产生数据,再喂数据(Feeding)
先生产数据,通过feed_dict喂数据(Feeding)的方式。
示例代码如下:
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()a = tf.placeholder(tf.int16)
b = tf.placeholder(tf.int16)
c = tf.add(a,b)a1 = 6
b1 = 8init = tf.global_variables_initializer()
with tf.Session() as sess:sess.run(init)print(sess.run(c,feed_dict = {a:a1,b:b1}))
③直接从文件中读取(Reading from file)
前两种方法虽然方便,但无法满足大型数据集训练时对速度要高效、内存消耗要小的要求。因此,TensorFlow提供了第三种方式,即在静态图(Graph)中定义好文件读取的方法,TensorFlow自动从文件(也就是文本或图片)中读取数据,然后解码成可用的样本集。
从文件读取数据的流程主要分为四个步骤:
①创建文件,准备数据
②创建文件名队列,将已准备的文件,按照随机顺序放入队列
③创建Reader,读取文件
④将读取的内容解码后输出

示例代码如下:
生成文件
import csvfile_name = "file.csv"
with open(file_name,"w",newline = "") as csvfile:writer = csv.writer(csvfile, dialect = "excel")with open("data1.txt","r") as file_txt:for line in file_txt:line_datas = str(line).strip("\n").split(",")print(line_datas)writer.writerow(line_datas)
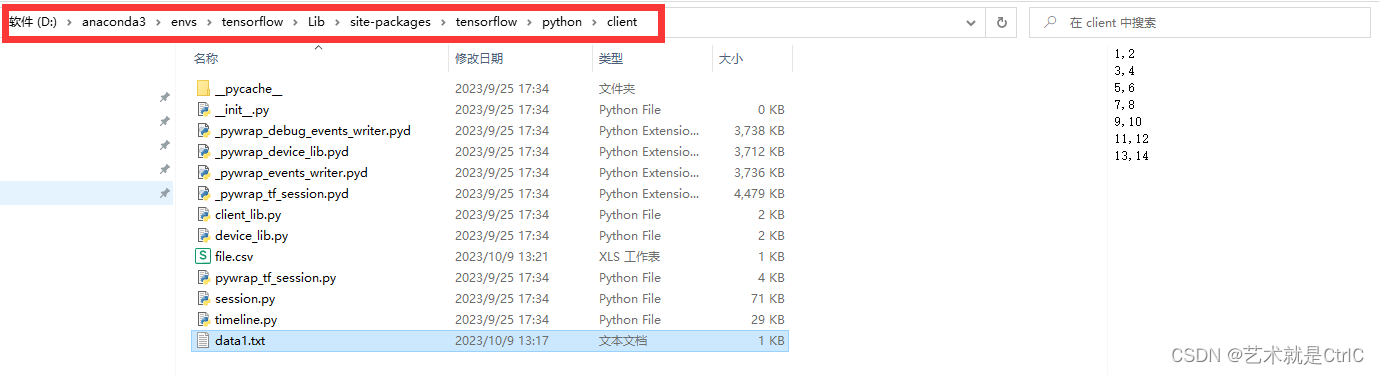
data1.txt的存放位置如下图,代码执行后会生成file.csv文件
读取文件
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()#要保存后csv格式的文件名
file_name_string = "file.csv"
filename_queue = tf.train.string_input_producer([file_name_string])
#定义reader,每次一行
reader = tf.TextLineReader()
key,value = reader.read(filename_queue)
#定义decoder
var1,var2 = tf.decode_csv(value,record_defaults = [[1.0],[1.0]])#运行图
init = tf.global_variables_initializer()
with tf.Session() as sess:sess.run(init)sess.run(tf.local_variables_initializer())#创建一个协调器,管理线程coord = tf.train.Coordinator()#启动QueueRunner,此时文件名队列已经进队threads = tf.train.start_queue_runners(coord = coord)for row in enumerate(open(file_name_string,"r")):e_val,l_val = sess.run([var1,var2])print(e_val,l_val)coord.request_stop()coord.join(threads)
读取图片
示例代码如下:
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()import os
import matplotlib.pyplot as pltfile_name = os.listdir("./image")
file_list = [os.path.join("./image",file) for file in file_name]#创建输入队列,默认顺序打乱
filename_queue = tf.train.string_input_producer(file_list,shuffle = True,num_epochs = 2)
key,image = tf.WholeFileReader().read(filename_queue)
#解码成tf中图像格式
image = tf.image.decode_jpeg(image)with tf.Session() as sess:sess.run(tf.local_variables_initializer())#创建一个协调器,管理线程coord = tf.train.Coordinator()threads = tf.train.start_queue_runners(coord = coord)for _ in file_list:#执行img = image.eval()plt.figure(1)plt.imshow(img)plt.show()coord.request_stop()coord.join(threads)