高端网站设计图片北京搜索引擎优化seo专员
文章目录
- 一. XSS攻击介绍
- 1. 前端安全
- 2. xss攻击简介
- 3. xss的攻击方式
- 二. java应对xss攻击的解决方案
- 1. 强制修改html敏感标签内容
- 2. 利用过滤器过滤非法html标签
一. XSS攻击介绍
1. 前端安全
随着互联网的高速发展,信息安全问题已经成为企业最为关注的焦点之一,而前端又是引发企业安全问题的高危据点。在移动互联网时代,前端人员除了传统的 XSS、CSRF 等安全问题之外,又时常遭遇网络劫持、非法调用 Hybrid API 等新型安全问题。当然,浏览器自身也在不断在进化和发展,不断引入 CSP、Same-Site Cookies 等新技术来增强安全性,但是仍存在很多潜在的威胁,这需要前端技术人员不断进行 “查漏补缺”。
2. xss攻击简介
XSS 全称 Cross Site Scripting,跨站脚本攻击。XSS攻击是指黑客往HTML文件中或者DOM中注入恶意脚本,从而在用户浏览页面时利用注入的恶意脚本对用户实施攻击的一种手段。
恶意脚本能够做事情有:
● 窃取Cookie信息。通过document.cookie获取Cookie信息。
● 监听用户行为。通过addEventListener接口监听事件。
● 修改DOM。如通过修改DOM伪造登录窗口,用来欺骗用户输入账号、密码等信息。
● 在页面内生成浮窗广告等
3. xss的攻击方式
XSS 攻击方式可以分为三种:存储型XSS攻击、反射型XSS攻击和基于DOM的XSS攻击。
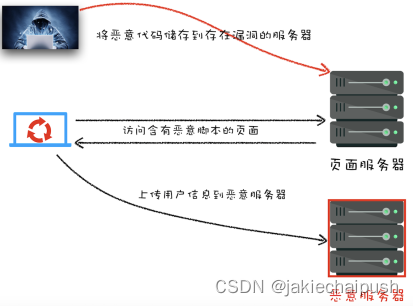
- 存储型xss攻击
黑客利用网站漏洞将恶意脚本提交并存储到网站服务器上。当用户浏览访问包含恶意脚本的页面时,恶意脚本就可以用户浏览器上执行,如将用户的Cookie信息等数据上传到服务器。
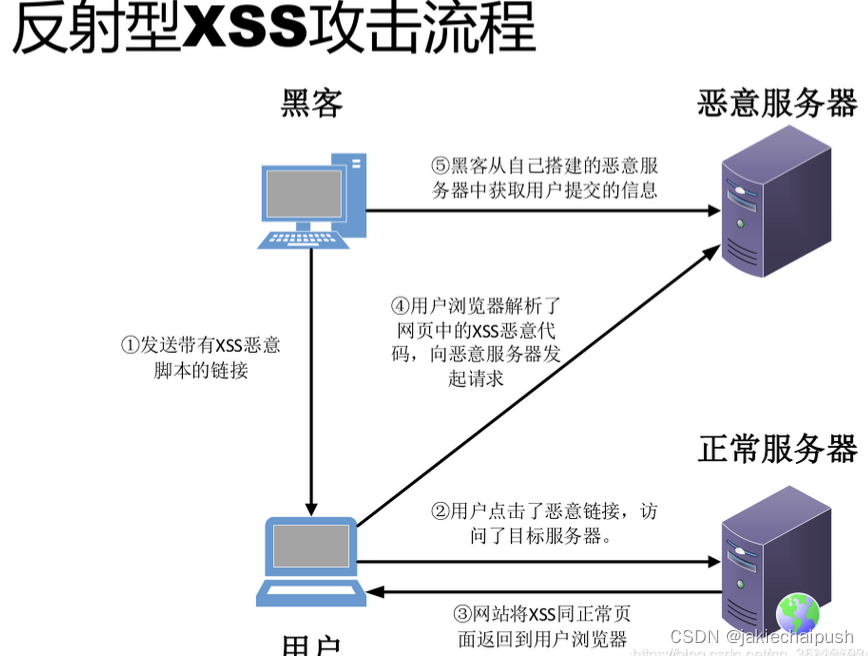
- 反射型xss攻击
在一个反射型XSS攻击过程中,恶意脚本属于用户发送给服务器请求的一部分,随后网站又把恶意脚本返回给用户。当恶意脚本在用户页面中被执行时,就可以利用该脚本做恶意操作。相比存储型XSS攻击,Web服务器是不会存储反射型XSS攻击的恶意脚本。
- 基于DOM的Xss攻击
基于 DOM 的 XSS 攻击是不牵涉到页面 Web 服务器的。具体来讲,黑客通过各种手段将恶意脚本注入用户的页面中,比如通过网络劫持在页面传输过程中修改 HTML 页面的内容,这种劫持类型很多,有通过 WiFi 路由器劫持的,有通过本地恶意软件来劫持的,它们的共同点是在 Web 资源传输过程或者在用户使用页面的过程中修改 Web 页面的数据。原始页面内容是没有问题的,黑客是通过各种手段在资源传输过程中或者用户使用页面过程中修改HTML的内容注入恶意脚本。
二. java应对xss攻击的解决方案
1. 强制修改html敏感标签内容
这是一种相对容易理解的方式,解决思路就是,当恶意注入的字段中,包含了类似这种html标签时,后台程序代码中强制替换或更改标签内容,这样存入数据库的内容再次返回至页面时,就不会以html的形式进行执行了
/*** xss特殊字符拦截与过滤** @author zhangcy* @date 2021-04016*/
public class XssStrUtils {/*** 滤除content中的危险 HTML 代码, 主要是脚本代码, 滚动字幕代码以及脚本事件处理代码* @param content 需要滤除的字符串* @return 过滤的结果*/public static String replaceHtmlCode(String content) {if (null == content) return null;if (0 == content.length()) return "";// 需要滤除的脚本事件关键字String[] eventKeywords = {"onmouseover", "onmouseout", "onmousedown", "onmouseup", "onmousemove", "onclick", "ondblclick","onkeypress", "onkeydown", "onkeyup", "ondragstart", "onerrorupdate", "onhelp", "onreadystatechange","onrowenter", "onrowexit", "onselectstart", "onload", "onunload", "onbeforeunload", "onblur","onerror", "onfocus", "onresize", "onscroll", "oncontextmenu", "alert"};content = replace(content, "<script", "<script", false);content = replace(content, "</script", "</script", false);content = replace(content, "<marquee", "<marquee", false);content = replace(content, "</marquee", "</marquee", false);content = replace(content, "'", "_", false);// 将单引号替换成下划线content = replace(content, "\"", "_", false);// 将双引号替换成下划线// 滤除脚本事件代码for (int i = 0; i < eventKeywords.length; i++) {content = replace(content, eventKeywords[i], "_" + eventKeywords[i], false); // 添加一个"_", 使事件代码无效}return content;}/*** 将字符串 source 中的 oldStr 替换为 newStr, 并以大小写敏感方式进行查找** @param source 需要替换的源字符串* @param oldStr 需要被替换的老字符串* @param newStr 替换为的新字符串*/private static String replace(String source, String oldStr, String newStr) {return replace(source, oldStr, newStr, true);}/*** 将字符串 source 中的 oldStr 替换为 newStr, matchCase 为是否设置大小写敏感查找** @param source 需要替换的源字符串* @param oldStr 需要被替换的老字符串* @param newStr 替换为的新字符串* @param matchCase 是否需要按照大小写敏感方式查找*/private static String replace(String source, String oldStr, String newStr,boolean matchCase) {if (source == null) return null;// 首先检查旧字符串是否存在, 不存在就不进行替换if (source.toLowerCase().indexOf(oldStr.toLowerCase()) == -1) return source;int findStartPos = 0;int a = 0;while (a > -1) {int b = 0;String str1, str2, str3, str4, strA, strB;str1 = source;str2 = str1.toLowerCase();str3 = oldStr;str4 = str3.toLowerCase();if (matchCase) {strA = str1;strB = str3;} else {strA = str2;strB = str4;}a = strA.indexOf(strB, findStartPos);if (a > -1) {b = oldStr.length();findStartPos = a + b;StringBuffer bbuf = new StringBuffer(source);source = bbuf.replace(a, a + b, newStr) + "";// 新的查找开始点位于替换后的字符串的结尾findStartPos = findStartPos + newStr.length() - b;}}return source;}}使用这种方式,即使前端恶意注入了某些非法的html标签,经过后端的过滤处理,返回的内容就不会执行html的相关操作事件了
2. 利用过滤器过滤非法html标签
第二种思路,考虑在过滤器中添加对所有请求接口的参数进行参数的拦截过滤,即程序认为的不合法标签都会自动做过滤,至于过滤的规则,可以借助现有的第三方组件,比如spring框架的htmlUtil类,这里使用hutool工具集提供的相关API做处理
- 导入依赖
<dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.5.9</version></dependency>
- 添加自定义过滤器增强包装类
ublic class XssHttpRequestWrapper extends HttpServletRequestWrapper {public XssHttpRequestWrapper(HttpServletRequest request) {super(request);}@Overridepublic String getParameter(String name) {String value = super.getParameter(name);if(!StringUtils.isEmpty(value)){value = HtmlUtil.filter(value);}return value;}@Overridepublic String[] getParameterValues(String name) {String[] values = super.getParameterValues(name);if(values!=null){for(int i=0;i<values.length;i++){String value = values[i];if(!StringUtils.isEmpty(value)){value = HtmlUtil.filter(value);}values[i]=value;}}return values;}@Overridepublic Map<String, String[]> getParameterMap() {Map<String, String[]> parameters = super.getParameterMap();Map<String, String[]> map = new LinkedHashMap<>();if(parameters !=null){for(String key : parameters.keySet()){String[] values = parameters.get(key);for(int i=0;i<values.length;i++){String value = values[i];if(!StringUtils.isEmpty(value)){value = HtmlUtil.filter(value);}values[i]=value;}map.put(key,values);}}return map;}@Overridepublic String getHeader(String name) {String value = super.getHeader(name);if(!StringUtils.isEmpty(value)){value = HtmlUtil.filter(value);}return value;}@Overridepublic ServletInputStream getInputStream() throws IOException {InputStream in = super.getInputStream();InputStreamReader reader = new InputStreamReader(in, Charset.forName("UTF-8"));BufferedReader buffer = new BufferedReader(reader);StringBuffer body = new StringBuffer();String line = buffer.readLine();while (line !=null){body.append(line);line = buffer.readLine();}buffer.close();reader.close();in.close();Map<String,Object> map = JSONUtil.parseObj(body.toString());Map<String,Object> result = new LinkedHashMap<>();for(String key : map.keySet()){Object val = map.get(key);if(val instanceof String){if(!StringUtils.isEmpty(val.toString())){result.put(key,HtmlUtil.filter(val.toString()));}}else {result.put(key,val);}}String json = JSONUtil.toJsonStr(result);ByteArrayInputStream bain = new ByteArrayInputStream(json.getBytes());return new ServletInputStream() {@Overridepublic boolean isFinished() {return false;}@Overridepublic boolean isReady() {return false;}@Overridepublic void setReadListener(ReadListener readListener) {}@Overridepublic int read() throws IOException {return bain.read();}};}
}
- 自定义过滤器并注入全局bean
ublic class XssFilter implements Filter {@Overridepublic void init(FilterConfig filterConfig) throws ServletException {}@Overridepublic void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {HttpServletRequest request = (HttpServletRequest)servletRequest;XssHttpRequestWrapper requestWrapper = new XssHttpRequestWrapper(request);filterChain.doFilter(requestWrapper,servletResponse);}@Overridepublic void destroy() {}
}
@Configuration
public class XSSFilterRegister {@Beanpublic FilterRegistrationBean<XssFilter> RegistTest1(){//通过FilterRegistrationBean实例设置优先级可以生效FilterRegistrationBean<XssFilter> bean = new FilterRegistrationBean<XssFilter>();bean.setFilter(new XssFilter());//注册自定义过滤器bean.setName("flilter");//过滤器名称bean.addUrlPatterns("/*");//过滤所有路径return bean;}}
通过这种方式,直接将注入的敏感标签符号去掉,这样确保了入库的数据的安全性,返回给页面的数据就不存在非法html标签问题了