官方网站下载手电筒今日时政新闻
说到django的全文检索,网上基本推荐的都是 haystack + whoosh + jieba 的方案。
由于我的需求对搜索时间敏感度较低,但是要求不能有数据的错漏。
但是没有调试的情况下,搜索质量真的很差,搞得我都想直接用Like搜索数据库算了。
但是峰回路转,还是让我找到几个信息,稍微优化了一下搜索结果。
1.haystack
haystack这层我增加了一个模糊搜索,即原本的text='q’变成了text__contains=‘q’。
搜索从原本的的content切换成了contains,不再需要完全匹配就能命中。
比如词“下雨”在用content的时候搜“雨”是没办法命中的,换成contain之后就可以了。(需要搭配第二点中的自定义全量分词,默认分词不行。具体原因不知,不过应该不是index的问题,因为我测试过用默认分词rebuild_index后,再切换ChineseAnalyzer而不重新rebuild_index依然可以搜索到结果,猜测原因应该是对搜索词的分词,但是我就一个字有啥好分词的?有懂得大佬麻烦教我一下。)
class LynSearchForm(SearchForm):def search(self):if not self.is_valid():return self.no_query_found()if not self.cleaned_data.get("q"):return self.no_query_found()# 原设置搜索条件的语句,被我替换成下面的语句# sqs = self.searchqueryset.auto_query(self.cleaned_data["q"]) sqs = self.searchqueryset.filter(text__contains=self.cleaned_data["q"])if self.load_all:sqs = sqs.load_all()return sqs
我写这篇文章的时间是2023年8月,haystack已经进行了大的更新。从原本的views.SearchView 切换到了 generic_views.SearchView。把接口都给换了,然后代码里面还是旧的内容,各位看官看的时候要注意。
新流程以SearchView为例:
form = self.get_form(form_class)
self.queryset = form.search()
context = self.get_context_data({self.form_name: form})
get_context_data是django的view的函数,所以我们要做的是在form上面做手脚。
2.whoosh + jieba
除了上面的操作外,还需要对jieba的ChineseAnalyzer进行自定义,修改成全量分词。
代码来源 州的先生 大佬写的MrDoc我从中受益良多,大家有兴趣可以多多支持
# coding:utf-8
# @文件: chinese_analyzer.py
# @创建者:州的先生
# #日期:2020/11/22
# 博客地址:zmister.comfrom whoosh.compat import u, text_type
from whoosh.analysis.filters import LowercaseFilter
from whoosh.analysis.filters import StopFilter, STOP_WORDS
from whoosh.analysis.morph import StemFilter
from whoosh.analysis.tokenizers import default_pattern
from whoosh.lang.porter import stem
from whoosh.analysis import Tokenizer, Token
from whoosh.util.text import rcompile
import jiebaclass ChineseTokenizer(Tokenizer):"""使用正则表达式从文本中提取 token 令牌。>>> rex = ChineseTokenizer()>>> [token.text for token in rex(u("hi there 3.141 big-time under_score"))]["hi", "there", "3.141", "big", "time", "under_score"]"""def __init__(self, expression=default_pattern, gaps=False):""":param expression: 一个正则表达式对象或字符串,默认为 rcompile(r"\w+(\.?\w+)*")。表达式的每一个匹配都等于一个 token 令牌。第0组匹配(整个匹配文本)用作 token 令牌的文本。如果你需要更复杂的正则表达式匹配处理,只需要编写自己的 tokenizer 令牌解析器即可。:param gaps: 如果为 True, tokenizer 令牌解析器会在正则表达式上进行分割,而非匹配。"""self.expression = rcompile(expression)self.gaps = gapsdef __eq__(self, other):if self.__class__ is other.__class__:if self.expression.pattern == other.expression.pattern:return Truereturn Falsedef __call__(self, value, positions=False, chars=False, keeporiginal=False,removestops=True, start_pos=0, start_char=0, tokenize=True,mode='', **kwargs):""":param value: 进行令牌解析的 Unicode 字符串。:param positions: 是否在 token 令牌中记录 token 令牌位置。:param chars: 是否在 token 中记录字符偏移。:param start_pos: 第一个 token 的位置。例如,如果设置 start_pos=2, 那么 token 的位置将是 2,3,4,...而非 0,1,2,...:param start_char: 第一个 token 中第一个字符的偏移量。例如, 如果设置 start_char=2, 那么文本 "aaa bbb" 解析的两个字符串位置将体现为 (2,5),(6,9) 而非 (0,3),(4,7).:param tokenize: 如果为 True, 文本应该被令牌解析。"""# 判断传入的文本是否为字符串,如果不为字符串则抛出assert isinstance(value, text_type), "%s is not unicode" % repr(value)t = Token(positions, chars, removestops=removestops, mode=mode,**kwargs)if not tokenize:t.original = t.text = valuet.boost = 1.0if positions:t.pos = start_posif chars:t.startchar = start_chart.endchar = start_char + len(value)yield telif not self.gaps:# The default: expression matches are used as tokens# 默认情况下,正则表达式的匹配用作 token 令牌# for pos, match in enumerate(self.expression.finditer(value)):# t.text = match.group(0)# t.boost = 1.0# if keeporiginal:# t.original = t.text# t.stopped = False# if positions:# t.pos = start_pos + pos# if chars:# t.startchar = start_char + match.start()# t.endchar = start_char + match.end()# yield tseglist = jieba.cut(value, cut_all=True)for w in seglist:t.original = t.text = wt.boost = 1.0if positions:t.pos = start_pos + value.find(w)if chars:t.startchar = start_char + value.find(w)t.endchar = start_char + value.find(w) + len(w)yield telse:# When gaps=True, iterate through the matches and# yield the text between them.# 当 gaps=True, 遍历匹配项并在它们之间生成文本。prevend = 0pos = start_posfor match in self.expression.finditer(value):start = prevendend = match.start()text = value[start:end]if text:t.text = textt.boost = 1.0if keeporiginal:t.original = t.textt.stopped = Falseif positions:t.pos = pospos += 1if chars:t.startchar = start_char + startt.endchar = start_char + endyield tprevend = match.end()# If the last "gap" was before the end of the text,# yield the last bit of text as a final token.if prevend < len(value):t.text = value[prevend:]t.boost = 1.0if keeporiginal:t.original = t.textt.stopped = Falseif positions:t.pos = posif chars:t.startchar = prevendt.endchar = len(value)yield tdef ChineseAnalyzer(expression=default_pattern, stoplist=None,minsize=2, maxsize=None, gaps=False, stemfn=stem,ignore=None, cachesize=50000):"""Composes a RegexTokenizer with a lower case filter, an optional stopfilter, and a stemming filter.用小写过滤器、可选的停止停用词过滤器和词干过滤器组成生成器。>>> ana = ChineseAnalyzer()>>> [token.text for token in ana("Testing is testing and testing")]["test", "test", "test"]:param expression: 用于提取 token 令牌的正则表达式:param stoplist: 一个停用词列表。 设置为 None 标识禁用停用词过滤功能。:param minsize: 单词最小长度,小于它的单词将被从流中删除。:param maxsize: 单词最大长度,大于它的单词将被从流中删除。:param gaps: 如果为 True, tokenizer 令牌解析器将会分割正则表达式,而非匹配正则表达式:param ignore: 一组忽略的单词。:param cachesize: 缓存词干词的最大数目。 这个数字越大,词干生成的速度就越快,但占用的内存就越多。使用 None 表示无缓存,使用 -1 表示无限缓存。"""ret = ChineseTokenizer(expression=expression, gaps=gaps)chain = ret | LowercaseFilter()if stoplist is not None:chain = chain | StopFilter(stoplist=stoplist, minsize=minsize,maxsize=maxsize)return chain | StemFilter(stemfn=stemfn, ignore=ignore,cachesize=cachesize)
重点是这个:

在PS2里面,结巴的大佬有提到有新功能(11年前的)jieba.cut_for_search()也可以试试
然后在whoosh_cn_backend.py里面修改ChineseAnalyzer。
from .chinese_analyzer import ChineseAnalyzer
# from jieba.analyse import ChineseAnalyzer
PS:这个jieba自带的ChineseAnalyzer也是我换的,如果你第一次搞这个,可以参考
https://blog.csdn.net/qiqiyingse/article/details/110299639
PS
1.HayStack
As of version 2.4 the views in haystack.views.SearchView are
deprecated in favor of the new generic views in
haystack.generic_views.SearchView which use the standard Django
class-based views which are available in every version of Django which
is supported by Haystack.
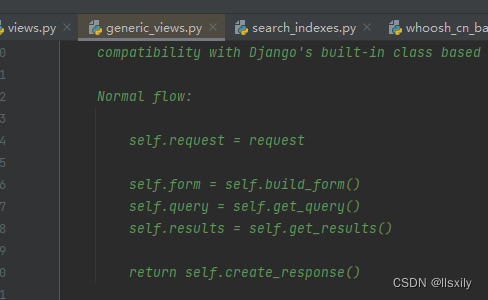
新代码,旧流程,可真有你的。
2.CSDN
稍微吐槽下CSDN,STONE大哥的文章里面,下面结巴的大佬在评论区有回复,结果评论显示的是2条,还好我点开看了一下。不然就错过了这么重要的信息。
https://blog.csdn.net/wenxuansoft/article/details/8169842
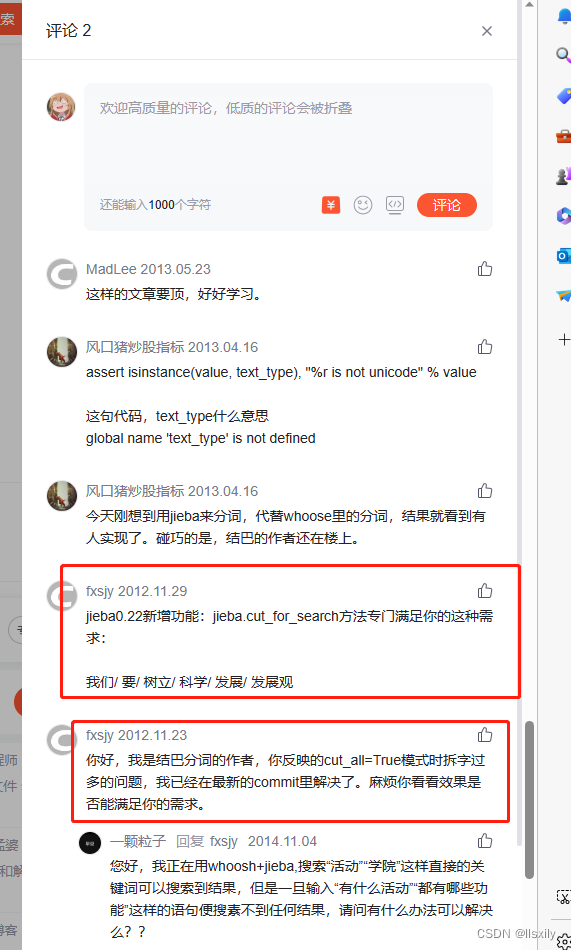
然后显示的热评是个灌水回答。。
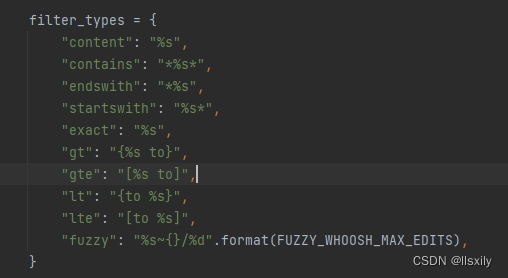
3.其他筛选参数
关于筛选的类型,在whoosh_cn_backend.py文件中,基本和django的差不多。