淄博论坛网站建设小程序推广平台
1. RDD的设计背景
在实际应用中,存在许多迭代式计算,这些应用场景的共同之处是,不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。但是,目前的MapReduce框架都是把中间结果写入到HDFS中,带来了大量的数据复制、磁盘IO和序列化开销。显然,如果能将结果保存在内存当中,就可以大量减少IO。RDD就是为了满足这种需求而出现的,它提供了一个抽象的数据架构,我们不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换处理,不同RDD之间的转换操作形成依赖关系,可以实现管道化,从而避免了中间结果的落地存储,大大降低了数据复制、磁盘IO和序列化开销。
2. RDD的概念
RDD(Resilient Distributed Datasets,弹性分布式数据集)代表可并行操作元素的不可变分区集合。
一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可以分成多个分区,每个分区就是一个数据集片段(HDFS上的块),并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算。
RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,不能直接修改,只能基于稳定的物理存储中的数据集来创建RDD,或者通过在其他RDD上执行确定的转换操作(如map、join和groupBy)而创建得到新的RDD。
RDD提供了一组丰富的操作以支持常见的数据运算,分为“行动”(Action)和“转换”(Transformation)两种类型,前者用于执行计算并指定输出的形式,后者指定RDD之间的相互依赖关系。两类操作的主要区别是,转换操作(比如map、filter、groupBy、join等)接受RDD并返回RDD,而行动操作(比如count、collect等)接受RDD但是返回非RDD(即输出一个值或结果)。
RDD典型的执行过程
Spark用Scala语言实现了RDD的API,程序员可以通过调用API实现对RDD的各种操作。RDD典型的执行过程如下:
1)RDD读入外部数据源(或者内存中的集合)进行创建;
2)RDD经过一系列的“转换”操作,每一次都会产生不同的RDD,供给下一个“转换”使用;
3)最后一个RDD经“行动”操作进行处理,并输出到外部数据源(或者变成Scala/JAVA集合或变量)。
需要说明的是,RDD采用了惰性调用,即在RDD的执行过程中,真正的计算发生在RDD的“行动”操作(行动算子底层代码调用了runJob函数),对于“行动”之前的所有“转换”操作,Spark只是记录下“转换”操作应用的一些基础数据集以及RDD生成的轨迹,即相互之间的依赖关系,而不会触发真正的计算。


val conf = new SparkConf
val sparkContext = new SparkContext(conf)
val lines :RDD = sparkContext.textFile(logFile)
//lines.filter((a:String) => a.contains("hello world"))
val count = lines.filter(_.contains("hello world")).count()
println(count)可以看出,一个Spark应用程序,基本是基于RDD的一系列计算操作。
第1行代码用于创建JavaSparkContext对象;
第2行代码从HDFS文件中读取数据创建一个RDD;
第3行代码对fileRDD进行转换操作得到一个新的RDD,即filterRDD;
count()是一个行动操作,用于计算一个RDD集合中包含的元素个数。
这个程序的执行过程如下:
1)创建这个Spark程序的执行上下文,即创建SparkContext对象;
2)从外部数据源(即HDFS文件)中读取数据创建fileRDD对象;
3)构建起fileRDD和filterRDD之间的依赖关系,形成DAG图,这时候并没有发生真正的计算,只是记录转换的轨迹;
4)执行action代码时,count()是一个行动类型的操作,触发真正的计算,开始执行从fileRDD到filterRDD的转换操作,并把结果持久化到内存中,最后计算出filterRDD中包含的元素个数。
3. spark任务的执行过程
每一个应用都是由driver端组成的,并且driver端可以解析用户的代码,并且在集群中并行执行,spark给大家提供了一个编程对象,它是一个抽象的,叫做弹性分布式数据集,这个数据集和一堆数据的集合并且是被分区的,因为分区的数据可以被并行的进行操作,rdd的创建方式有两种 1.读取hdfs的文件 2.在driver的一个集合可以转换为rdd,rdd可以被持久化到内存中,并且rdd可以实现更好的失败恢复容错。

为什么rdd是抽象的呢?因为rdd并不存在数据,它是虚拟的,我们在定义逻辑的时候要标识一个节点,表示数据在流动到此处的时候要进行什么样的处理,我们可以理解rdd是一个代理对象。

上述任务执行过程可以划分为两个stage,从创建rdd开始到groupBy的shuffle,划分为一个stage,然后该shuffle到任务执行结束,又是一个stage。后面读源码我们会发现,当出现shuffle时,就要划分出一个阶段。因为业务逻辑发生了变化。
任务的执行和层架关系:
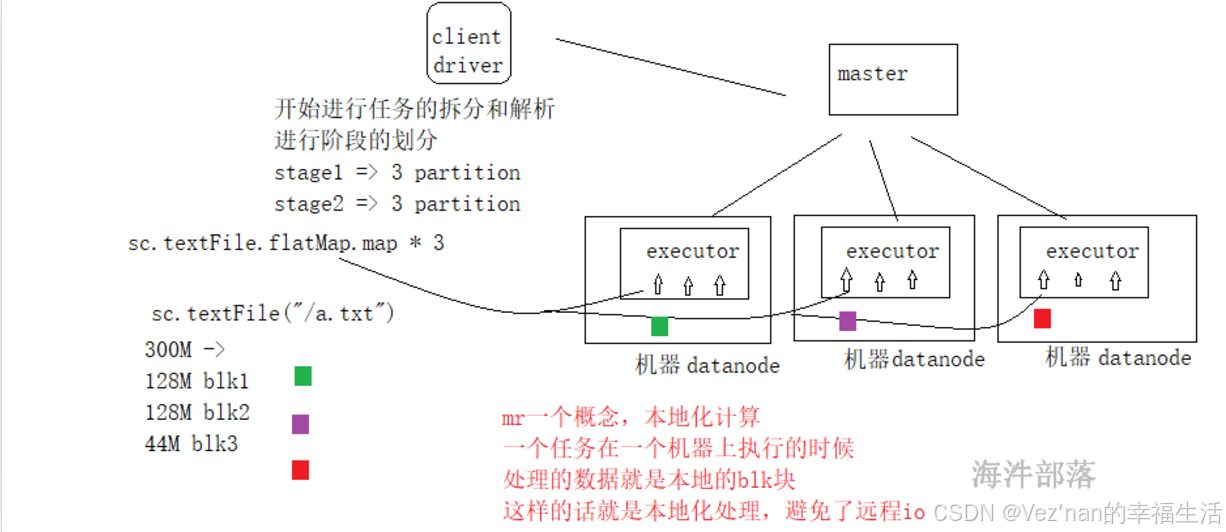
读取hdfs数据的时候映射应该是一个blk块对应一个分区
- 在一个任务中,一个action算子会生成一个job。(行动算子的源码都会包含runJob函数)
- 在一个job中存在shuffle算子,比如group sort切分阶段,shuffle+1个阶段。
- shuffle是任务的划分的重点,前面的任务会将数据放入到自己的本地存储,后续的任务进行数据的拉取。
- 在一个stage中任务都是管道形式执行的,避免了io,序列化和反序列化,这个就是dag切分的原理。
- 在一个阶段中分区数量就是task任务的数量,task任务就是一堆非shuffle类算子的整体任务链。
- 有几个分区就会并行的执行几个task任务。
- 有几个分区是根据读取的文件来进行适配的,比如有三个blk那么就会生成三个分区,因为我们可以在每个分区中进行处理数据,实现本地化的处理,避免远程io。
我们知道,分区的个数与读取的文件的Split切片数量有关。假如textFile读取文件的大小为400M,则会被物理切分为3个block,因为每个block-size的大小最大为128M,block1为128M,block2为128M,block3为144M。默认逻辑切片split-size的大小与block-size相适配,为128M,所以有三个分区。三个分区就会并行的执行3个task任务。
spark中一个executor可以执行多个task任务。这是通过将executor配置为拥有多个cores来实现的。每个核心可以并行执行一个task。即executor是一个JVM进程,负责在节点上运行任务。可以为executor配置多个核心来并行处理多个任务。
如果分区数多于executor的核心数,某些task必须等待其他task任务完成才能开始执行。