营销型企业网站建设教案北京网站优化常识
目录
- Mysql
- group by和 distinct哪个性能好
- java
- 觉得Optional类怎么样
- isEmpty和isBlank的用法区别
- 使用大对象时需要注意什么
- 内存溢出和内存泄漏的区别及详解
- Spring
- @Resource和@Autowired的起源
- 既生“@Resource”,何生“@Autowired”
- 使用@Autowired时为什么Idea会曝出黄色警告
- 使用@Resource时为什么Idea不会曝出黄色警告
- @Autowired和@Resource使用场景
Mysql
group by和 distinct哪个性能好
先说结论:
- 在语义相同,有索引的情况下:
group by和distinct都能使用索引,效率相同。因为group by和distinct近乎等价,distinct可以被看做是特殊的group by。 - 在语义相同,无索引的情况下:
distinct效率高于group by。原因是distinct 和 group by都会进行分组操作,但group by在Mysql8.0之前会进行隐式排序,导致触发filesort,sql执行效率低下。而从Mysql8.0开始,Mysql就删除了隐式排序,所以,此时在语义相同,无索引的情况下,group by和distinct的执行效率也是近乎等价的。
二者均可用时建议使用group by: 相比于distinct来说,group by的语义明确。且由于distinct关键字会对所有字段生效,在进行复合业务处理时,group by的使用灵活性更高,group by能根据分组情况,对数据进行更为复杂的处理,例如通过having对数据进行过滤,或通过聚合函数对数据进行运算。
再说过程:
-
distinct的使用
单列去重时:DISTINCT 关键词用于返回唯一不同的值。放在查询语句中的第一个字段前使用,且作用于主句所有列。如果列具有NULL值,并且对该列使用DISTINCT子句,MySQL将保留一个NULL值,并删除其它的NULL值,因为DISTINCT子句将所有NULL值视为相同的值。
多列去重时:distinct多列的去重,则是根据指定的去重的列信息来进行,即只有所有指定的列信息都相同,才会被认为是重复的信息。 -
group by的使用
对于基础去重来说,group by的使用和distinct类似: 两者的语法区别在于,group by可以进行单列去重,group by的原理是先对结果进行分组排序,然后返回每组中的第一条数据。且是根据group by的后接字段进行去重的。 -
distinct和group by原理
在大多数例子中,DISTINCT可以被看作是特殊的GROUP BY,它们的实现都基于分组操作,且都可以通过松散索引扫描、紧凑索引扫描来实现
DISTINCT和GROUP BY都是可以使用索引进行扫描搜索的,所以,在一般情况下,对于相同语义的DISTINCT和GROUP BY语句,我们可以对其使用相同的索引优化手段来进行优化。但对于GROUP BY来说,在MYSQL8.0之前,GROUP Y默认会依据字段进行隐式排序。filesort就是排序,这个单词出现在explain中时一定要谨慎,这是一个非常耗费性能的操作。
隐形排序:
对于隐式排序,我们可以参考Mysql官方的解释:GROUP BY 默认隐式排序(指在 GROUP BY 列没有 ASC 或 DESC 指示符的情况下也会进行排序)。然而,GROUP BY进行显式或隐式排序已经过时(deprecated)了,要生成给定的排序顺序,请提供 ORDER BY 子句。
所以,在Mysql8.0之前,Group by会默认根据作用字段(Group by的后接字段)对结果进行排序。在能利用索引的情况下,Group by不需要额外进行排序操作;但当无法利用索引排序时,Mysql优化器就不得不选择通过使用临时表然后再排序的方式来实现GROUP BY了。
且当结果集的大小超出系统设置临时表大小时,Mysql会将临时表数据copy到磁盘上面再进行操作,语句的执行效率会变得极低。这也是Mysql选择将此操作(隐式排序)弃用的原因。
基于上述原因,Mysql在8.0时,对此进行了优化更新:从前(Mysql5.7版本之前),Group by会根据确定的条件进行隐式排序。在mysql 8.0中,已经移除了这个功能,所以不再需要通过添加order by null 来禁止隐式排序了,但是,查询结果可能与以前的 MySQL 版本不同。要生成给定顺序的结果,请按通过ORDER BY指定需要进行排序的字段。
java
觉得Optional类怎么样
if(user!=null){Address address = user.getAddress();if(address!=null){String province = address.getProvince();}
}
java认为以上写法是比较丑陋的,为了避免上述丑陋的写法,让丑陋的设计变得优雅。JAVA8提供了Optional类来优化这种写法。
Optional可以理解为一个集合,里面只有你的对象,类似于ThreadLocal<>();并且它的用法也有些类似,其实就是先set值,然后再取值,或者做一些判断和转化。
好像代码的本质,无非就是 set、get、transf、judge
- Optional(T value),empty(),of(T value),ofNullable(T value) :作用类似于set
- orElse(T other),orElseGet(Supplier other)和orElseThrow(Supplier exceptionSupplier) : 作用类似于judge
- map(Function mapper)和flatMap(Function> mapper):作用类似于transf
- isPresent()和ifPresent(Consumer consumer) : 类似于get
// 应用场景1
public String getCity(User user) throws Exception{if(user!=null){if(user.getAddress()!=null){Address address = user.getAddress();if(address.getCity()!=null){return address.getCity();}}}throw new Excpetion("取值错误");}public String getCity(User user) throws Exception{return Optional.ofNullable(user).map(u-> u.getAddress()).map(a->a.getCity()).orElseThrow(()->new Exception("取指错误"));
}// 应用场景2
if(user!=null){dosomething(user);
}Optional.ofNullable(user).ifPresent(u->{dosomething(u);
});// 应用场景3
public User getUser(User user) throws Exception{if(user!=null){String name = user.getName();if("zhangsan".equals(name)){return user;}}else{user = new User();user.setName("zhangsan");return user;}
}public User getUser(User user) {return Optional.ofNullable(user).filter(u->"zhangsan".equals(u.getName())).orElseGet(()-> {User user1 = new User();user1.setName("zhangsan");return user1;});
}
评价:Optional大体属于链式编程,虽然代码优雅了。但是,逻辑性没那么明显,可读性有所降低,大家项目中看情况酌情使用。
isEmpty和isBlank的用法区别
-
StringUtils.isEmpty()
是否为空。可以看到 " " 空格是会绕过这种空判断,因为是一个空格,并不是严格的空值,会导致 isEmpty(" ")=falseStringUtils.isEmpty(null) = true StringUtils.isEmpty("") = true StringUtils.isEmpty(" ") = false StringUtils.isEmpty(“bob”) = false StringUtils.isEmpty(" bob ") = false -
StringUtils.isBlank()
是否为真空值(空格或者空值)StringUtils.isBlank(null) = true StringUtils.isBlank("") = true StringUtils.isBlank(" ") = true StringUtils.isBlank(“bob”) = false StringUtils.isBlank(" bob ") = false
评价:统一使用isBlank
使用大对象时需要注意什么
一个根据客户号查询客户有多少订单的内部使用接口,接口的返回是 List<订单>,看起来没啥毛病,对不对?
一般来说一个个人客户就几十上百,多一点的上千,顶天了的上万个订单,一次性拿出来也不是不可以。
但是有一个客户不知道咋回事,特别钟爱我们的平台,也是我们平台的老客户了,一个人居然有接近 10w 的订单。
然后这么多订单对象搞到到项目里面,本来响应就有点慢,上游再发起几次重试,直接触发 Full gc,降低了服务响应时间。
所以,经过这个事件,我们定了一个规矩:用 List、Map 来作为返回对象的时候,必须要考虑一下极端情况下会返回多少数据回去。即使是内部使用,也最好是进行分页查询。
list、map、json、等等可能很大的对象,使用时一定要限制size。
内存溢出和内存泄漏的区别及详解
-
内存溢出(Out Of Memory)
是程序在申请内存时,没有足够的内存空间供其使用。比如:你需要10M的空间,内存空间只剩8M,这就会出现内存溢出。
以栈举例:栈满时在做进栈必定产生空间溢出,叫上溢,栈空时在做退栈也产生空间溢出,称为下溢。就是分配的内存不足以放下数据项序列,称为内存溢出。 -
内存泄漏 (Memory Leak)
是程序在申请内存后,无法释放已申请的内存空间,一次内存泄露危害可以忽略,但内存泄露堆积后果很严重。memory leak最终会导致out of memory。
这块内存不释放,就不能再用了,就叫这块内存泄漏了。 -
内存泄漏分类
- 常发性内存泄漏。发生内存泄漏的代码会被多次执行到,每次被执行的时候都会导致一块内存泄漏。
- 偶发性内存泄漏。发生内存泄漏的代码只有在某些特定环境或操作过程下才会发生。常发性和偶发性是相对的。对于特定的环境,偶发性的也许就变成了常发性的。所以测试环境和测试方法对检测内存泄漏至关重要。
- 一次性内存泄漏。发生内存泄漏的代码只会被执行一次,或者由于算法上的缺陷,导致总会有一块仅且一块内存发生泄漏。比如,在类的构造函数中分配内存,在析构函数中却没有释放该内存,所以内存泄漏只会发生一次。
- 隐式内存泄漏。程序在运行过程中不停的分配内存,但是直到结束的时候才释放内存。严格的说这里并没有发生内存泄漏,因为最终程序释放了所有申请的内存。但是对于一个服务器程序,需要运行几天,几周甚至几个月,不及时释放内存也可能导致最终耗尽系统的所有内存。所以,我们称这类内存泄漏为隐式内存泄漏。
从用户使用程序的角度来看,内存泄漏本身不会产生什么危害,作为一般的用户,根本感觉不到内存泄漏的存在。
真正有危害的是内存泄漏的堆积,这会最终消耗尽系统所有的内存。从这个角度来说,一次性内存泄漏并没有什么危害,因为它不会堆积,而隐式内存泄漏危害性则非常大,因为较常发性和偶发性内存泄漏它更难被检测到。 -
内存溢出的原因及解决方案
修改JVM启动参数,直接增加内存。
检查错误日志,查看“OutOfMemory”错误前是否有其它异常或错误。
对代码进行走查和分析,找出可能发生内存溢出的位置。
使用内存查看工具动态查看内存使用情况。 -
出现内存溢出和内存泄露,重点排查几点
- 检查对数据库查询中,是否有一次获得全部数据的查询。一般来说,如果一次取十万条以上记录到内存,就可能引起内存溢出。这个问题比较隐蔽,在上线前,数据库中数据较少,不容易出问题,上线后,数据库中数据多了,一次查询就有可能引起内存溢出。因此对于数据库查询尽量采用分页的方式查询,查多少字段用多少字段。
- 检查代码中是否有死循环或递归调用。
- 检查是否有大循环重复产生新对象实体。
- 检查List、MAP等集合对象是否有使用完后,未清除的问题。List、MAP等集合对象会始终存有对对象的引用,使得这些对象不能被GC回收。使用list.clear()或者map.clear()
Spring
@Resource和@Autowired的起源
提到Spring依赖注入,大家最先想到应该是@Resource和@Autowired,但是大家有没有想过@Resource又支持名字又支持类型,还要@Autowired干嘛?
是的,没错,他们两个其实还是有核心区别的,了解一个东西绝不能只看其作用,一定要关注其产生的背景,从背景了解一件事才能知其然且知其所以然
-
@Resource 于 2006年5月11日随着JSR 250 发布 ,官方解释是:
Resource 注释标记了应用程序需要的资源。该注解可以应用于应用程序组件类,或组件类的字段或方法。当注解应用于字段或方法时,容器将在组件初始化时将所请求资源的实例注入到应用程序组件中。如果注释应用于组件类,则注释声明应用程序将在运行时查找的资源。可以看到@Resource 其实类似一个定义,讲述了要实现的功能。其他的任何组件或框架都可以自由实现该功能。
JSR是Java Specification Requests的缩写,意思是Java 规范提案。是指向JCP(Java Community Process)提出新增一个标准化技术规范的正式请求。任何人都可以提交JSR,以向Java平台增添新的API和服务。JSR已成为Java界的一个重要标准。
-
@Autowired 于 2007年11月19日随着Spring2.5发布,官方解释是:
将构造函数、字段、设置方法或配置方法标记为由 Spring 的依赖注入工具自动装配。可以看到,@Autowired 是 Spring按照@Resource注解的功能自己实现的一个注解,它们的功能非常相似。那么为什么spring已经支持了@Resource,又要自己搞个@Autowired呢?
对此,Spring2.5的官方文档有一段相关的解释,大概的意思是说,Spring2.5 支持注解自动装配啦, 现已经支持JSR-250 @Resource 基于每个方法或每个字段的命名资源的自动装配,但是只有@Resource是不行的,我们还推出了“粒度”更大的@Autowired,来覆盖更多场景了。
核心点:Resource是java的原生注解,Autowired是spring的自定义注解
既生“@Resource”,何生“@Autowired”
由背景可知,粒度就是@Resource和@Autowired的和核心区别了!
- @Autowired:类型注入
- @Resource:名字注入优先,找不到名字找类型
论功能的“粒度”,@Resource已经包含@Autowired了啊,“粒度”更大啊。
此时很凌乱,那么“粒度”到底指的是什么?在混迹众多论坛后,其中stackoverflow的一段话引起了我的注意:
大概的意思是:Spring虽然实现了两个功能类似的,但是存在概念上的差异或含义上的差异:
- @Resource 这按名称给我一个确定已知的资源。
- @Autowired 尝试按类型连接合适的其他组件。
但是@Resource当按名称解析失败时会启动。在这种情况下,它会按类型解析,引起概念上的混乱,因为开发者没有意识到概念上的差异,而是倾向于使用@Resource基于类型的自动装配。
原来Spring官方说的“粒度”是指“资源范围”,@Resource找寻的是确定的已知的资源,相当于给你一个坐标,你直接去找。@Autowired是在一片区域里面尝试搜索合适的资源。
所以上面的问题答案已经基本明确了。
Spring为什么会支持两个功能相似的注解呢?
-
它们的概念不同,@Resource更倾向于找已知资源,而Autowired倾向于尝试按类型搜索资源。
-
方便其他框架迁移,@Resource是一种规范,只要符合JSR-250规范的其他框架,Spring就可以兼容。
既然@Resource更倾向于找已知资源,为什么也有按类型注入的功能?
- 个人猜测:可能是为了兼容从Spring切换到其他框架,开发者就算只使用Resource也是保持Spring强大的依赖注入功能。
使用@Autowired时为什么Idea会曝出黄色警告
使用@Autowired在属性上的时候Idea会曝出黄色的警告,并且推荐我们使用构造方法注入,而Resource就不会,这是为什么呢?警告如下:

其实Spring文档中已经给出了答案,主要有这几点:
- 声明不了常量的属性
基于属性的依赖注入不适用于声明为 final 的字段,因为此字段必须在类实例化时去实例化。声明不可变依赖项的唯一方法是使用基于构造函数的依赖项注入。 - 容易忽视类的单一原则
一个类应该只负责软件应用程序功能的单个部分,并且它的所有服务都应该与该职责紧密结合。如果使用属性的依赖注入,在你的类中很容易有很多依赖,一切看起来都很正常。但是如果改用基于构造函数的依赖注入,随着更多的依赖被添加到你的类中,构造函数会变得越来越大,代码开始就开始出现“异味”,发出明确的信号表明有问题。具有超过十个参数的构造函数清楚地表明该类有太多的依赖,让你不得不注意该类的单一问题了。因此,属性注入虽然不直接打破单一原则,但它却可以帮你忽视单一原则。 - 循环依赖问题
A类通过构造函数注入需要B类的实例,B类通过构造函数注入需要A类的实例。如果你为类 A 和 B 配置 bean 以相互注入,使用构造方法就能很快发现。 - 依赖注入强依赖Spring容器
如果您想在容器之外使用这的类,例如用于单元测试,不得不使用 Spring 容器来实例化它,因为没有其他可能的方法(除了反射)来设置自动装配的字段。
使用@Resource时为什么Idea不会曝出黄色警告
在官方文档中,我没有找到答案,查了一些资料说是:@Autowired 是 Spring 提供的,一旦切换到别的 IoC 框架,就无法支持注入了. 而@Resource 是 JSR-250 提供的,它是 Java 标准,我们使用的 IoC 容器应该和它兼容,所以即使换了容器,它也能正常工作。
@Autowired和@Resource使用场景
记住一句话就行,@Resource倾向于确定性的单一资源,@Autowired为类型去匹配符合此类型所有资源。
如集合注入,@Resource也是可以的,但是建议使用@Autowired。idea左侧的小绿标可以看出来,不建议使用@Resource注入集合资源,本质上集合注入不是单一,也是不确定性的。
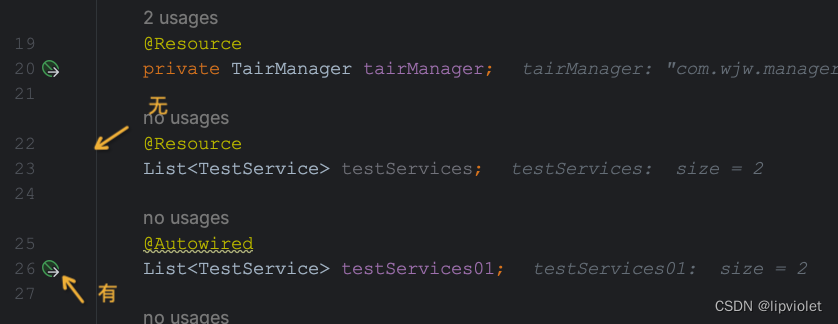
@Resource装配顺序:
-
如果同时指定了name和type,则从Spring上下文中找到唯一匹配的bean进行装配,找不到则抛出异常。
-
如果指定了name,则从上下文中查找名称(id)匹配的bean进行装配,找不到则抛出异常。
-
如果指定了type,则从上下文中找到类似匹配的唯一bean进行装配,找不到或是找到多个,都会抛出异常。
-
如果既没有指定name,又没有指定type,则自动按照byName方式进行装配;如果没有匹配,则回退为一个原始类型进行匹配,如果匹配则自动装配。
@Resource的作用相当于@Autowired,只不过@Autowired按照byType自动注入。